Informations of general interest (it may be).
INDICE
Mi e' stato richiesto molte volte come viene fatto un cavo RJ45. Siccome puo' essere di utilita' generale ho pensato di sciverlo una volta per tutte e metterlo sul WEB
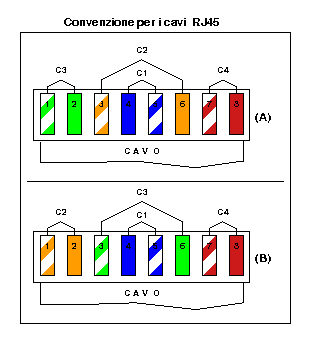
Di cavi RJ45 ne esistono di due tipi: diritto o invertito.
Per fare un cavo diritto dopo aver ordinato accuratamente gli otto (8) fili secondo lo schema (A) della figura e tagliati della lunghezza appropiata inseriteli nell'apposito connettore avendo cura ti mantenere lo stesso rivolto verso l'alto (cioe' la sua parte attiva) e finalmente grimpateli. Ripetete la stessa operazione dall'altro capo del filo.
Per fare un cavo invertito si procede come per il cavo diritto avendo cura di seguire l'ordine degli otto fili secondo lo schema (A) della figure per una estremita' e secondo lo schema (B) per l'altra.
Dopo un po' di errori imparerete a tagliare i fili correttamente (della stessa lunghezza) ed a inserirli negli appositi alloggiamenti del connettore. Buon lavoro.
Credo che tutti noi siamo oltremodo annoiati di ricevere un grande numero di messaggi MAIL in cui la lista delle persone che ricevono lo stesso e' di gran lunga piu' lunga del messaggio stesso. La cosa oltre ad essere annoiante spreca anche notevoli risorse sia di rete che di spazio disco. Credo quindi sia di interesse generale imparare ad usare le LISTE di distribuzione che tra l'altro semplificano la vita di chi deve coordinare gruppi di lavoro. L'unico problema, ma se ci pensate bene e' una virtu', non e' conveniente (diciamo cosi') fare il REPLAY a questi messaggi.
Per avere le suddette istruzioni che riguardano l'uso di PINE mi sono rivolto a Massimo Masera che molto gentilmente mi ha inviato le istruzioni che riproduco qui sotto.
Definire una lista di distribuzione in PINE e' semplice, ma, secondo me, limitante rispetto al VMS in quanto PINE gestisce direttamente l'addressbook cioe' il file che contiene gli alias e le liste. Non si puo' quindi usare come LISTA un file testo che contenga semplicemente l'elenco dei destinatari (tipo .dis nel VMS); bisogna immettere a mano l'elenco usando PINE stesso (oppure scrivendo delle procedure ad hoc che convertano elenchi da formato arbitrario a formato PINE).Per definire una lista in PINE si fa cosi'. Dopo aver invocato PINE ottenete sullo schemo la seguente videata:
Main MENU di pine
? HELP - Get help using Pine
C COMPOSE MESSAGE - Compose and send a message
I FOLDER INDEX - View messages in current folder
L FOLDER LIST - Select a folder to view
A ADDRESS BOOK - Update address book
S SETUP - Configure or update Pine
Si sceglie:
"A ADDRESS BOOK - Update address book"di qui si da' A (sta per add new) e si ottiene (tra parentesi <> quello che bisogna mettere):
Nickname :Fullname : Fcc : Comment : Addresses :
Si salva con
ctrl-XSi aggiorna con il comando
V [View/Edit]da PINE.
Per mandare ora un messaggio alla lista appena creata (COMCAL) si procede come segue:
1) Si va in "COMPOSE MESSAGE" e si ottiene questo:
To : Cc : Attchmnt: Subject :A questo punto di da' CTRL-R (rich header) e si ottiene questo:
To : Cc : Bcc : Newsgrps: Fcc : sent-mail Lcc : Attchmnt: Subject :
Basta mettere il nome della distribution list nel campo Lcc (List carbon copy) ed il gioco e' fatto. Il campo Bcc serve per mandare il messaggio in "Blind carbon copy". In pratica ha lo stesso effetto di Lcc, ma si puo' usare senza ricorrere a liste. Per usare Bcc credo che sia necessario (non l'ho verificato) mettere un destinatario nel campo "To". Con Lcc invece non si mette nulla nel campo "To"; basta la lista.
Chi volesse sapere un po' piu' di PINE faccia riferimento al seguente documento di Claudio Allocchio che contiene le nozioni di base per gli utenti.
Per un bel tutorial di PINE date una occhiata a quello originale della University of Washington. Se volete saperne ancora di piu andate al PINE originator dove vi consiglio di leggere le FAQ.
Come usare le code di stampa dei teorici.
In questo capitoletto descrivero' brevemente il problema delle code di STAMPA dei teorici soffermandomi solo su quelle code che fanno riferimento a stampanti che sono in rete (ovviamente intendo rete ETHERNET) in quanto le vecchie stampanti seriali sono veramente molto lente ed obsolete, li lasceremo morire di morte naturale, per cui devo scusarami con quei ricercatori che fanno riferimento al piano terra del vecchio edificio che non e' provvisto di tali stampanti.
Per prima cosa ricordo che il Gruppo IV della Sezione INFN di Torino ed il Dipartimento di Fisica Teorica ha a disposizione per stampare le seguenti stampanti di rete:
Tutte queste stampanti sono PostScript Level II. Le due macchine multi-funzione Xerox sono molto moderne in quanto sono allo stesso tempo fotocopiatrici, stampanti ed eventualmente anche scanner. mentre la LN17PS, della DIGITAL, e' solo stampante. E' stata la prima stampante di rete ed incomincia a risentire del pesante lavoro svolto.
Ovviamente queste macchine per poter stampare devono fare riferimento a delle code definite sulle varie CPU del nostro sistema informatico. Qui mi occupero' solo del OVMS e delle macchine UNIX che afferiscono al cluster centrale. I vari utilizzatori di LINUX devono aggiustarsi da soli, ma normalmente sono bravi. Non mi interessero' delle macchine MS.
OVMS Volgarmente Sistema VAX
Sulle macchine che operano con questo sistema operativo sono state definite le seguenti printer Queue
SHOW SYMPer quanto mi riguarda, avendo poca memoria e non avendo voglia di ricordarmi troppi nomi, vi suggerisco di introdurre nel costro login.com la linea :
LP_X*EROX :== @TO4CVS_SYS$GRP04:[UTLNAN.A2PS]LPXEROX.COMche definisce il comando lp_x (ovviamente in nome puo' essere cambiato a vostro piacimento). Questo comando fa riferimento ad una procedura DCL che ho scritto e che a mio modo di vedere facila il nostro compito, stampare una file. Infatti definito il simbolo suddetto per stampare la file myfile.type basta dare il comando:
lp_x myfile.type nome_coda
Sara' la procedura stessa ad accorgersi se cercate di stampare una file PostScript (PS) o una file testo. Vi ricordo che tuttle le stampanti sono solo PS per cui le file testo devo essere opportunamente filtrate prima di essere stampate.
UNIX
Sul sistema centrale UNIX sono state definite le seguenti printer Queue (non e' stato possibile mantenere i nomi del VMS in quanto UNIX interpreta a sua modo il $.)
lpr -Pnome_coda myfile.psse la file che volete stampare e' una file PostScrip (PS), mentre se la file che volete stampare e' una file di testo (per esempio un listato) usate allora il comando
a2ps -Pnome_coda myfile.type
Dove a2ps e' un programma che converte il file testo (alphanumerico) in file PostScrpt (PS). Puo' darsi che non troverete subito il comando a2ps, cercatelo con il comando find di UNIX e modificate opportumente il vostro PATH o definitevi un alias.
Vi ricordo che per controllare se le code summenzionate sono viste dal sistema che state usando basta inviare il comando:
cat /etc/printcapche lista tulle le code che sono state definite per quel sistema.
Se avete un programma molto grosso (cioe' con molte linee e molte subroutine) e siete annoiati, dopo ogni piccola modifica, di aspettare che le operazioni di compilazione a link siano terminate vi sonsiglio di spezzare il vostro listato in diversi pezzi (non necessariamente una file per subroutine o function) e quindi usare il comando make del sistema operativo.
Qui di sotto ho raccolto un po di informazioni sul come scrivere la file di descrizione (makefile) che costituisce l'input di make.
############################################################################### # The make command updates one or more target names by executing commands in # a description file. This file is passed to the make command via the option # # -f makefile # # If you do not use the -f flag, make looks in the current directory for a # description file named makefile or Makefile. # # NB: The make command updates the target based on whether the target's # dependencies have been modified relative to the time of last # modification to the target, or if the target itself does not exist. # # Description Files # The description file can contain a sequence of entries that define # dependencies. These entries are referred to as dependency lines. # A dependency line is defined as follows: # # target : [dependency...] [; command...] # # The dependency line, starting at the leftmost margin, begins with the # - target. Specify a single target. The target is separated from its # dependencies by a : (colon). # - The dependencies are listed sequentially separated by a single space. # - It is also possible to place a command line after the dependency list, # as long as it is prefaced by a ; (semicolon). # - one can avoid the use of ; (has is done in the examples) making # sure that the fist character of the line is alike in the last # line of the example # - To indicate to make that the current line continues to the next line, # place a \ (backslash) as the last character in the line. # - Comment lines begin with # (number sign) and all text following this # symbol up to the end of the line is considered part of the comment. # # For more details confer to the appropriat man pages. # # gzp Dicember 1998 ############################################################################### # # the simple makefile for grazing_9 # # This program consist of the following file: # # grazing_9.f file with main # graz_sub.f file with subroutine # akyuz_lib.f " " " # algularmom_lib.f " " " # fys_lib.f " " " # interpolate_lib.f " " " # math_lib.f " " " # leg_1.f " " " # leg_2.f " " " # leg_3.f " " " # leg_4.f " " " # # and makes calls to several routines of the NAG library # ############################################################################### # ### some macro-name (alias) definition # PROJECTS = grazing_9 # PROGRAM = grazing_9.o \ graz_sub.o \ akyuz_lib.o \ algularmom_lib.o \ fys_lib.o \ interpolate_lib.o \ math_lib.o \ leg_1.o \ leg_2.o \ leg_3.o \ leg_4.o # PRG_LIBF = akyuz_lib.f \ algularmom_lib.f \ fys_lib.f \ interpolate_lib.f \ math_lib.f # NAGLIB = -L/teo/lib -lnag # ### the main command for the makefile # grazing_9: $(PROGRAM) ;\ f77 $(PROGRAM) $(NAGLIB) -o grazing_9 # ### the commands to produce all the obj # grazing_9.o: grazing_9.f ;\ f77 -c grazing_9.f # graz_sub.o : graz_sub.f ;\ f77 -c graz_sub.f # graz_lib.o : $(PRG_LIBF) ;\ f77 -c $(PRG_LIBF # leg_1.o : leg_1.f ;\ f77 -c leg_1.f # leg_2.o : leg_2.f ;\ f77 -c leg_2.f # leg_3.o : leg_3.f ;\ f77 -c leg_3.f # leg_4.o : leg_4.f f77 -c leg_4.f # notice the first character is a TAB character # ###############################################################################
Spero che queste informazioni siano utili e che vi permettano di usare make per essere piu' efficienti e di risparmiare un po' del vostro tempo.
OBS! le LIBRARIES del OVMS sono ARCHIVES in UNIX
Puo' essere utile sapere che le vecchie librerie del OVMS in UNIX si chiamano archivi, per cui i vecchi comandi lib/create e lib/list (che si usava per conoscere il contenuto di una libreria) devono essere sostituiti con il comando ar.
Per esempio la creazione di un archivio, diciamo libgeom.a
puo' essere fatta
con il comando:
ar -c -r libgeom.a d3j.o d6j.o d9j.o cgc.o
ovviamente dopo aver compilato con con la devute opzioni le file
d3j.o, d6j.8, ....
Qui' sotto riproduto un estatto delle man pages con le opzioni che mi sono piu' utili.
The (ar) utility creates and maintains groups of files combined into a sin-
gle archive file. Generally, you use this utility to create and update
library files that the link editor uses; however, you can use the archiver
for any similar purpose.
When ar creates an archive, it creates administrative information in a for-
mat that is portable across all machines. When the archive contains at
least one object file that ar recognizes as such, an archive symbol table,
which the link editor uses to search the archive file, is created. When-
ever ar is used to create or update the contents of such an archive, the
symbol table is rebuilt. The -s option forces the symbol table to be
rebuilt.
The following options are supported:
-a Positions new files in the archive after the existing file named by the
posname parameter.
-b Positions new files in the archive before the existing file named by
the posname) parameter.
-d Deletes the specified files from the archive file.
-p Prints the contents of the specified files from the archive. If no
files are specified, the contents of all files are printed in the order
of the archive.
-q Quickly appends the specified files to the end of the archive file.
The archiver does not check whether the added members are already in
the archive. This is useful to bypass the searching otherwise done when
creating a large archive piece by piece.
-r Replaces or adds the specified files to archive. If the archive named
by archive does not exist, a new archive file is created. Files that
replace existing files do not change the order of the archive. New
files are appended to the archive.
-s [XPG4-UNIX] Makes a symbol definition (symdef file) as the first file
of an archive. This file contains a hash table of ranlib structures
and a corresponding string table. If you change the archive contents,
the symdef file becomes obsolete because archive file symbols change.
The ar command builds the symbol table by default.
-t Prints a table of contents for the files in archive. The table
includes the files specified by the file operands. If no file names
are specified, all files in archive are included in the order of the
archive.
CONDOR e' un sistema di BATCH distribuito su WAN (tutta la rete INFN) e che non e' intrusivo. L'utente della macchina continua a lavorare senza il minimo problema in quanto CONDOR, quando una macchina viene usata, ha un sistema di pointer che permette al sistema stesso di trasferire il job su una altra CPU del sistema che non e' usata (cioe' non e' in user_mode).
Questo sistema verra' di fatto installato su tutte le macchine INFN in quanto si e' riscontrato che la capacita' di calcolo dell'ente e' in larga parte inutilizzata. Inoltre CONDOR costituisce un prodotto stategico per l'ente nella utilizzazione della WAN.
Qui, se siete interessati, trovate il manuale on-line e il tutorial che conviene consultare.
Se volete selezionare le macchine di torino inserite il comando CONDOR:
rank = $(SUBMIT_UID_DOMAIN) == "to.infn.it"
Qui di sotto riproduco le istruzioni necessarie per sottomettere il job su CONDOR, ovviamente tutti i nomi che trovate si riferiscono a delle mie directories e a dei miei file. Spero che questo serva a chiarire le istruzioni. Li ho discusse a fondo con Mazzanti, uno degli esperti di CONDOR. Gli errori ovviamente sono miei
Per utilizzare il sistema di batch distribuito "CONDOR" e' necessario:
1) compilare il file con
condor_compile compilatore nome_file
2) sottomettere il batch al pool di condor con
condor_submit file.cmd
dove file.cmd e' un file che ha questo formato:
########################################################################
## ##
## Test Condor command file ##
## ##
########################################################################
#
executable = xxxxx ! il file .exe
input = xxxxx.in ! contiene for005, sys$input
output = xxxxx.out ! contiene for006, sys$output
error = xxxxx.err
log = xxxxx.log
nice_user = True
queue
#
########################################################################
3) controllare lo stato del job con
condor_q e
condor_status
4) aspettare la fine del job che verra' segnalata attraverso un mail
Per ciascuno dei comandi citati esiste un help on-line che e' possibile
visualizzare utilizzando l'opzione -h del comando stesso.
Il manuale completo di condor si trova in
http://server11.infn.it/condor/condor-V6_1-Manual/Index.htm
I nodi da cui e' possibile utilizzare condor sono tutte le macchine del
gruppo IV (sia LINUX che ALPHA) e su alcune macchine centrali come la
to01xd, to02xd, to03xd.
-----------------------------------------------------------------------
Un esempio di Istruzioni per un mio job da Paolo Mazzanti
-----------------------------------------------------------------------
Caro Nanni,
mi sembra che un possibile modo per runnare il tuo programma con condor
sia il seguente:
Condor submit file:
# ---------------------------------------------------------------
# run element for wkbm: condor
# ---------------------------------------------------------------
#
executable = /usr/users/nanni/wkb/wkbm_a.remote
initialdir = /usr/users/nanni/wkb/examples
input = wkm_a.input
output = wkbm_a.out
error = wkbm_a.err
log = wkb.log
queue
#
L'insieme che segue dovrebbe essere chiamato input.dat e risiedere in
/usr/users/nanni/wkb/examples
64.,28.,238.,92.,388.
-60.,1.15,0.702
-20.,1.15,0.6
60,260,2,120
60,130,2
ffniu.dat
1.e+4
-40.,5.,1.
0
0.,0.
/usr/users/nanni/wkb/pbarrier.dat
#
**************** compilazione e link per condor *********************
condor_compile f77 -L/teo/lib -lnag wkbm_a.f -o wkbm_a.remote
ovviamente wkbm_a.remote
dovra' essere in
/usr/users/nanni/wkb
*********************************************************************
Fammi sapere....
Paolo
------------------------------------------------------------------------
| Paolo Mazzanti |
| I.N.F.N. and Dept. of Physics Via Irnerio 46, 40126 Bologna, Italy|
| Phones: +39051-351136, 6305222 |
| Fax: +39051-247244 |
| mailto:mazzanti@bo.infn.it |
------------------------------------------------------------------------
La NAG library nella Sezione di Torino
La NAG-library Mark 19 e' disponibile sia sul sistema linux sia sul sistema UNIX per ALPHA. Si trovano su/teosw/libNel montare la Mark 19, per dare tempo agli utenti di fare gli upgrade necessari dei loro programmi, abbiamo mantenuto la vecchia versione (Mark 18) copiandola sotto il nome nag18 (con ovvia notazione) per cui se volete usare la vecchia libreria sempicemente modificate i vostri makefile o script sostituendo nag con nag18
Qui troverete i manuali della nuova libreria Mark 19. Per poterli consultare il vostro brouser deve poter accedere ad Acroread.
Prima di fare gli upgrade consultate il capitolo: Advice on replacement calls for withdrawn/supersided routines